AWS
Auto Scaling 최적화 - 안정성과 비용 효율을 동시에 잡는 법
heesoohi
2025. 5. 15. 15:32
AWS의 Auto Scaling 기능은 애플리케이션의 가용성을 유지하면서도 리소스를 효율적으로 관리할 수 있는 중요한 도구이다. 하지만 설정을 어떻게 하느냐에 따라 불필요한 인스턴스 생성, 불안정한 성능, 예상치 못한 비용 증가가 발생할 수 있다.
Auto Scaling이 너무 자주 작동한다면?
Auto Scaling 그룹이 너무 자주 스케일 아웃(인스턴스 증가)과 스케일 인(인스턴스 감소)을 반복하면 다음과 같은 문제가 발생할 수 있다:
- 비용 증가: 인스턴스가 짧은 시간이라도 실행되면 비용이 발생
- 불안정한 서비스: 인스턴스가 충분히 안정화되기도 전에 종료됨
- 의미 없는 반응: 사소한 트래픽 변화에도 과도하게 반응
최적화를 위한 두 가지 핵심 조정 포인트
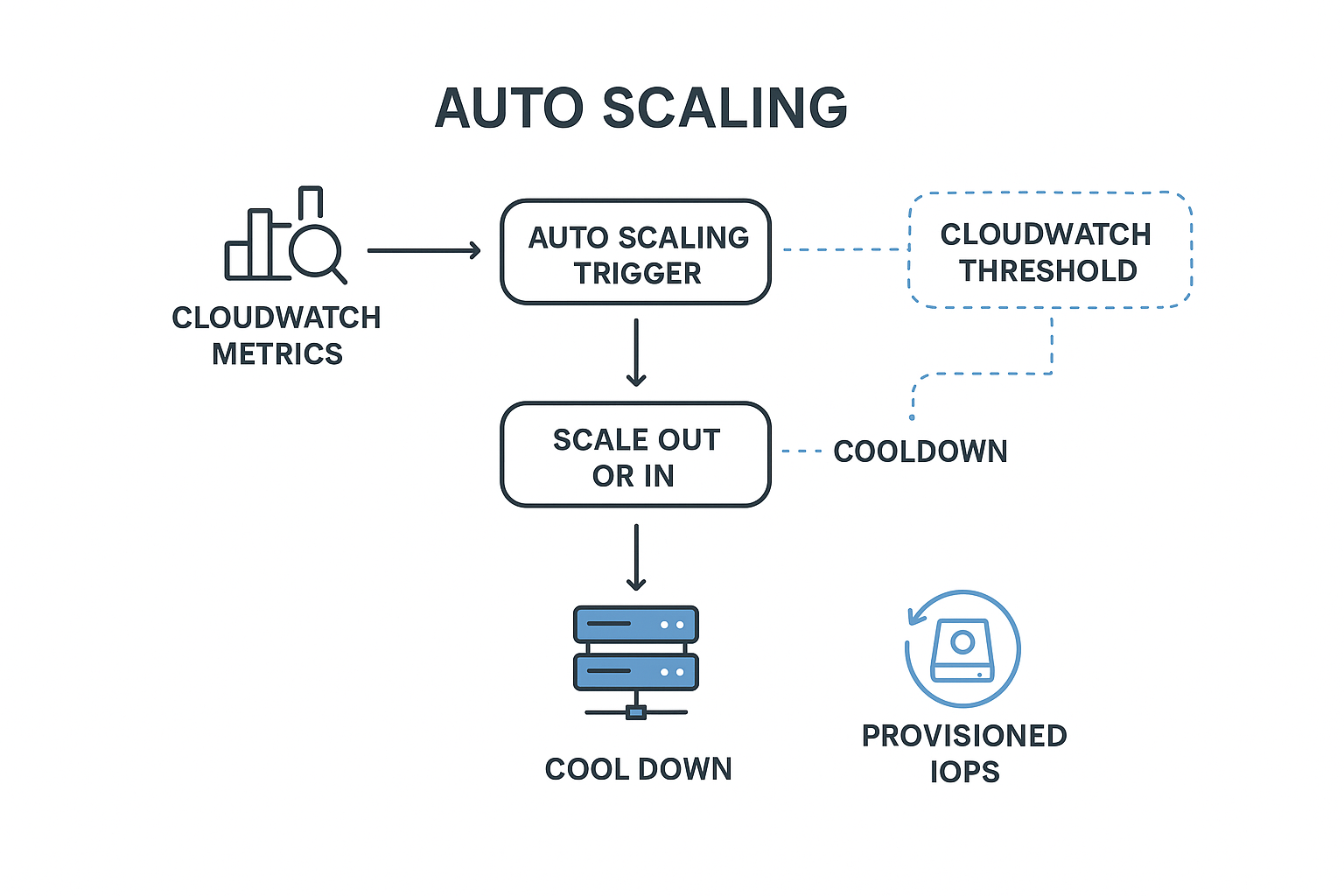
1. 휴지 기간(Cooldown Period) 늘리기
- 역할: 스케일 아웃/인 이벤트가 발생한 후, 일정 시간 동안 추가 스케일링을 막음
- 효과: 반복적인 스케일링 방지 → 더 예측 가능하고 안정적인 동작 유도
2. CloudWatch 지표 임계값 높이기
- 역할: CPU 사용률, 네트워크 트래픽 등 특정 지표가 기준값을 초과할 때만 스케일 아웃/인 발생
- 문제점: 임계값이 낮으면 사소한 부하에도 스케일링
- 해결책: CPU 40% → 60~70% 등으로 상향 조정 → 진짜 부하 상황에만 반응
💡 이 두 가지 조정만으로도 쓸데없는 인스턴스 증감을 줄이고, 비용 최적화 + 서비스 안정성을 동시에 잡을 수 있다!
➡️ 임계값과 휴지 기간을 늘리면 오히려 탄력성이 떨어지지 않을까? 하는 고민도 있었지만, 실제로는 그 반대였다.
| 오해 | 실제 효과 |
| 반응이 느려지면 탄력성 저하 | 오히려 안정적으로 대응 가능 |
| 빠르게 반응해야만 탄력적이다 | 필요할 때만 정확히 반응하는 것이 진짜 탄력성 |
| 자주 스케일링이 유리하다 | 잦은 인스턴스 증감은 서비스 품질 저하 + 비용 증가로 이어짐 |
정리하자면 Auto Scaling은 자동화된 리소스 관리를 제공하는 강력한 도구지만, 기본 설정만으로는 예기치 못한 문제가 생길 수 있다. 이런 문제를 줄이기 위해서는 서비스 특성에 맞는 조정이 필요하며, 위와 같은 방법들이 그 출발점이 될 수 있다.